Data indexing on Solana blockchain
Introduction
The Solana blockchain, like all L1 layer blockchains, is a decentralized ledger that stores all transaction information for every user interaction with the blockchain. These interactions include transfers, swaps, farming, or minting NFTs.
Each transaction contains sequential user history information and is often aggregated to derive meaningful statistics. These statistics range from querying how much yield a user has earned from farming in a month to simply tallying the number of transactions a user has conducted per month. Companies that build dApps on blockchains, such as decentralized exchanges, need to display information such as exchange pool offerings for swapping and track metrics like total volume and fees received per day.
This introduces the challenge of using the blockchain as a database. Query requests pass through RPC node endpoints, and retrieving and parsing transactions takes time. It’s inefficient to aggregate multiple transactions for a single query. Therefore, there’s a need to index all transactions and store them for efficient processing and querying, which brings databases into play. Considering frequent join queries and the ratio of read requests to write, a transactional SQL database is a suitable choice. Additionally, placing a cache in front of the database can reduce the database load during periods of high read requests per second.
Data Indexing
The process of indexing event data on the Solana blockchain can be categorized into several steps:
- Retrieve all confirmed signatures from the Solana chain using the RPC endpoint call
getConfirmedTransactions. - For each signature, obtain detailed transaction information via the RPC endpoint call
getParsedTransactions. - Parse the transaction log and events using the program IDL.
- Store the parsed information in the database.
Code Sample
import * as anchor from "@coral-xyz/anchor";
import {BorshCoder, EventParser, web3} from "@coral-xyz/anchor";
const limit = 100;
const options = {
until: until,
before: before,
limit: limit
};
const programId = new web3.PublicKey("<Program ID>")
const programIdl = "<Program IDL>"
const connection =
new Connection(clusterApiUrl("mainnet-beta"));
const batch = await connection
.getConfirmedSignatures(programId, options);
const transactions = await Promise.all(
batch.map(signature =>
connection.getParsedTransaction(signature)
)
)
const eventParser = new EventParser(
programId,
new BorshCoder(programIdl));
const events = eventParser
.parseLogs(tx.meta.logMessages);
// store events to database
...These steps can be modularized and executed as standalone components to scale out the system. Specifically, step 1 involves polls at an interval, retrieving and processing signatures in batches rather than all at once. A checkpoint needs to be read and stored at the beginning and end of the process to prevent instances from double processing the same batch task. The additional steps for each instance are as follows:
- Retrieve the last processed signature checkpoint from the database, considering pending transactions within the visibility timeout.
- Add a checkpoint with pending status to the database.
- Retrieve all confirmed signatures from the Solana chain starting from the checkpoint signature using the RPC endpoint call
getConfirmedTransactions. - For each signature, obtain detailed transaction information via the RPC endpoint call
getParsedTransaction. - Parse the transaction log and events using the program IDL.
- Store the parsed information in the database.
- Update the last processed signature checkpoint in the database.
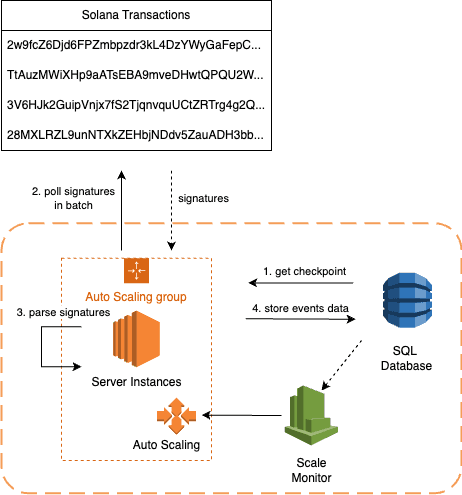
Depending on the RPC endpoint request limit and the computing power of each instance, the batch size can be limited, ensuring that each instance processes only a set number of signatures at a time. The visibility timeout can be configured based on how frequently pending requests are repeated. With this setup, an asynchronous queue system architecture is established to scale out the workload.
This setup offers the advantage of easy scalability. If the number of transactions increases and the indexing process falls behind, more instances can be added. An alarm trigger can be set up to automatically scale out more instances based on the difference between pending and processed signatures.
Event Table Sample
CREATE TABLE IF NOT EXISTS public.events
(
program_id text,
program_name text,
signature text,
slot numeric,
epoch numeric,
fee numeric,
compute_unit_consumed numeric,
fee_payer text,
event_name text,
event_data jsonb,
accounts jsonb,
log text,
id uuid NOT NULL DEFAULT gen_random_uuid(),
CONSTRAINT events_pkey PRIMARY KEY (id)
);Now that all events and logs are indexed in the database, SQL queries can be run to aggregate information based on the program and event name. Views can also be created to speed up queries using indexes and cache.
Conclusion
In conclusion, indexing event data on the Solana blockchain is crucial for efficient querying and processing of transactions. By modularizing the indexing process and implementing a scalable architecture, we can effectively manage the increasing volume of transactions on the blockchain.
Using a transactional SQL database, along with caching mechanisms, enables us to optimize query performance while handling large amounts of data. With the ability to scale out by adding more instances as needed, we ensure that the indexing process can keep pace with the growing demands of the blockchain ecosystem.
By leveraging these techniques, dApp developers and companies can build robust applications on the Solana blockchain that offer responsive and reliable user experiences.